NeurIPS 2023 HomeRobot: Open Vocabulary Mobile Manipulation (OVMM) Challenge

|
Hardware Stack: HomeRobot GitHub |
Overview

Prize: A Hello-Robot Stretch RE2 🤖😏 *
The objective of the HomeRobot: Open Vocabulary Mobile Manipulation (OVMM) Challenge is to create a platform that enables researchers to develop agents that can navigate unfamiliar environments, manipulate novel objects, and move away from closed object classes towards open-vocabulary natural language. This challenge aims to facilitate cross-cutting research in embodied AI using recent advances in machine learning, computer vision, natural language, and robotics.
HomeRobot OVMM challenge provides:
- a realistic goal description with challenging multi-step tasks
- multi-room interactive environments
- a large and diverse object asset library, in support of an open-vocabulary mobile-manipulation task
- continuous action space – both navigation + manipulation
- real-world counterpart benchmark
Hello-Robot is sponsoring the challenge so the winner will receive their own Stretch robot (a $25k value)!
Data
We have designed 3D simulated homes in Habitat. These environment are realistically complex, and cluttered with articulated objects, receptacles, and a large array of assets. Hello-Robot Stretch can then be trained and evaluated in simulation with the same control stack as on physical hardware. Agents that can accurately navigate around, search for, and manipulate objects in simulation will be transferred to the real world benchmark. No static data or human traces are provided. Participants are encouraged to utilize the rich simulated environment for fast iteration and training of reinforcement learning-based policies.

Environments
The evaluation is in two phases: Stage 1 is simulation, while Stage 2 is run on our physical hardware in FAIR’s mock apartment space in Fremont, CA. The challenge is setup such that APIs and therefore models can be seamlessly shared between the simulation benchmark and physical hardware. Our goal, is in part, to enable researchers without access to hardware to evaluate their approaches in the real world.
Stage 1: Simulation 1
Below are example scenes from the simulation benchmark. Participants do not require a robot to compete, instead performing entirely in simulation. We will then take the best performing simulation systems and run them on our held-out physical hardware environment (see blow)

|

|
The environments all contain multiple rooms with varying layounts. An example top-down layout is presented on the right. For the examples here, we have removed small objects and clutter that will be present in the actual evaluation. |
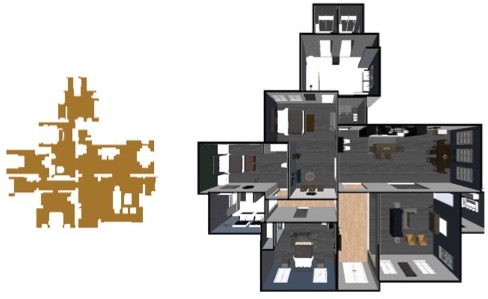
|
Stage 2: Physical Robot 2
Once systems have been tested in simulation, we will transfer the most competitive entries to a physical robot. Below you can see part of the physical robot evaluation environment hosted by Meta in Fremont California. The unseen evaluation settings will change or introduce furniture, object locations, and object types (not pictured).

The software stack is designed to be easy to use and has therefore also been tested in university labs. We invite you to try the stack even if you do not plan to submit to the challenge. To help advance robotics research and fair benchmarking, our stack is designed to quickly on-board new researchers into robotics research. Everything is written in python with no knowledge of ROS required. The full open-source software stack is available at github.com/facebookresearch/home-robot.
Metrics
Participating entries will be evaluated using the following three metrics – both in simulation for the automatic leaderboard and on the physical robot:
- Overall Success A trial is successful if, at the end of the trial, the specified object is anywhere on top of a target receptacle of the correct category. Anywhere on top of the surface is acceptable. If at any point the real robot collides with scene geometry, the task fails immediately.
- Partial Success In addition to the overall success, we report success for each of the four individual sub-tasks: (1) finding the target object on a start receptacle, (2) grasping the object, (3) finding the goal receptacle, and (4) placing the object on the goal receptacle (full success). We assign partial credit based on the partial success: the average number of sub-tasks completed. We use this incremental partial credit as a tiebreaker, in case multiple submissions result in the same overall success.
- Number of steps The number of steps needed to solve the episode.
The above metrics will be averaged over the evaluation episodes, and standard errors will be computed across episodes to produce confidence bounds when comparing participant submissions. We will also provide the participants additional analytics such as the number of interactions with objects.
We reserve the right to use additional metrics to choose winners in case of statistically insignificant differences.
Participation Guidelines
Please don’t hesitate to reach out with questions to homerobot-info@googlegroups.com
Stage 1: Simulation 1
We will use EvalAI 3 to host the challenge. Participants should register for the competition on the EvalAI challenge page and create a team. Participants need to upload docker containers with their agents.
The challenge will consist of the following phases/splits that allow participants to organize their work:
- Minival phase: The purpose of this phase is sanity checking — to confirm that remote evaluation reports the same result as local evaluation. Each team is allowed up to 100 submissions per day. We will disqualify teams that spam the servers.
- Test standard phase: The purpose of this phase/split is to serve as the public leaderboard establishing the state of the art. This is what should be used to report results in papers. Each team is allowed up to 10 submissions per day, to be used judiciously.
- Test challenge phase: This split will be used to decide challenge teams who will proceed to Stage 2 Evaluation. Each team is allowed a total of 5 submissions until the end of challenge submission phase. The highest performing of these 5 will be automatically chosen.
The agents will be evaluated on an AWS GPU-enabled instance. Agents will be evaluated on 1000 episodes and will have a total available time of 48 hours to finish each run. Submissions will be evaluated on AWS EC2 p2.xlarge instance which has a Tesla K80 GPU (12 GB Memory), 4 CPU cores, and 61 GB RAM.
Note: Before pushing the submissions for remote evaluation, participants should test the their submission docker locally to make sure it is working.
Stage 2: Physical Robot 2
A full open-source control stack will be released by Meta AI (the github discussed above is currently in beta), in collaboration with Hello Robot, for the hardware challenge. Once systems have been successfully tested and ranked in simulation, we will evaluate top-3 teams on a physical robot. The final evaluation scenario is a fully held-out apartment with novel objects. All participants’ code will be run with the same default calibrations for fair comparison. We will reset the scene to several predefined configurations. Robots will be run repeatedly on each scene to allow for demonstration of repeatability and statistical significance testing of the results.
Dates
| Challenge Starts | June 19, 2023 |
| Simulator Leaderboard opens | July 12, 2023 |
| Leaderboard closes, Eval on physical robots | Oct 10, 2023 |
| Evaluation results examined | Oct 20, 2023 |
| Winners announced and invited to contribute | Oct 30, 2023 |
| Presentation at NeurIPS 2023 | Dec, 2023 |
Results
HomeRobot OVMM Challenge Workshop talk at NeurIPS’2023 video and slides for download .
HomeRobot OVMM Challenge Leaderboard (sorted by Success Rate)
| Rank | Team | Success (Sim) | Success (Real) |
|---|---|---|---|
| 1 | UniTeam | 0.108 | 0.5 |
| 2 | Rulai | 0.032 | 0.0 |
| 3 | KuzHum (RL YOLO+DETIC (full tracker +) | 0.024 | 0.0 |
| 4 | LosKensingtons (Longer) | 0.020 | |
| 5 | GXU-LIPE-Li (xtli312/maniskill2023:heuristi) | 0.016 | |
| 6 | GVL | 0.016 | |
| 7 | VCEI | 0.012 | |
| 8 | USTCAIGroup * (baseline_rl_with_heuristic) | 0.008 | |
| 9 | BigDong * (v2+nogaze_v0.2) | 0.008 | |
| 10 | Piano * (V2wogaze) | 0.008 | |
| 11 | PoorStandard (RGBD) | 0.008 | |
| 12 | Clear (harobo2.2hr) | 0.004 | |
| 13 | scale_robotics | 0.004 | |
| 14 | Deep Bit | 0.004 | |
| 15 | BigGE * (no gaze) | 0.000 |
(Real world experiments were run only for the top 3 teams)
Challenge Winners Talks
1st Place: UniTeam, Andrew Melnik, Michael Büttner, Leon Harz, Lyon Brown, Gora Chand Nandi, Arjun PS, Gaurav Kumar Yadav, Rahul Kala, Robert Haschke
1st Place talk slides download and technical report.
2nd Place: Rulai Team Yang Luo, Jinxin Zhu, Yansen Han, Bingyi Lu, Xuan Gu, Qinyuan Liu, Yaping Zhao, Qiting Ye, Chenxiao Dou, Yansong Chua
2nd Place talk slides download.
3rd Place: Kuzhum Team Volodymyr Kuzma, Vladyslav Humennyy, Ruslan Partsey
3rd Place talk slides download and technical report.
HomeRobot OVMM White Paper
We have also posted a more extensive white paper about the OVMM benchmark which includes details of how the environments were constructed, the baselines defined/trained, the hardware setup we used, and a more comprehensive treatment of the related literature: HomeRobot: Open-Vocabulary Mobile Manipulation [arXiv] [low-res 8MB]
Citing Challenge
@inproceedings{homerobotovmmchallenge2023, title = {Towards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge}, author = {Sriram Yenamandra and Arun Ramachandran and Mukul Khanna and Karmesh Yadav and Jay Vakil and Andrew Melnik and Michael Büttner and Leon Harz and Lyon Brown and Gora Chand Nandi and Arjun PS and Gaurav Kumar Yadav and Rahul Kala and Robert Haschke and Yang Luo and Jinxin Zhu and Yansen Han and Bingyi Lu and Xuan Gu and Qinyuan Liu and Yaping Zhao and Qiting Ye and Chenxiao Dou and Yansong Chua and Volodymyr Kuzma and Vladyslav Humennyy and Ruslan Partsey and Jonathan Francis and Devendra Singh Chaplot and Gunjan Chhablani and Alexander Clegg and Theophile Gervet and Vidhi Jain and Ram Ramrakhya and Andrew Szot and Austin Wang and Tsung-Yen Yang and Aaron Edsinger and Charlie Kemp and Binit Shah and Zsolt Kira and Dhruv Batra and Roozbeh Mottaghi and Yonatan Bisk and Chris Paxton}, booktitle = {Thirty-seventh Conference on Neural Information Processing Systems: Competition Track}, url = {https://arxiv.org/abs/2407.06939}, year = {2023} }
Citing Paper
For convenience, we are also including BibTex for the white paper if you’re interested in the benchmark and software stack, rather than the challenge
@inproceedings{homerobotovmm, title = {HomeRobot: Open Vocab Mobile Manipulation}, author = {Sriram Yenamandra and Arun Ramachandran and Karmesh Yadav and Austin Wang and Mukul Khanna and Theophile Gervet and Tsung-Yen Yang and Vidhi Jain and Alex William Clegg and John Turner and Zsolt Kira and Manolis Savva and Angel Chang and Devendra Singh Chaplot and Dhruv Batra and Roozbeh Mottaghi and Yonatan Bisk and Chris Paxton}, booktitle = {Conference on Robot Learning}, url = {https://arxiv.org/abs/2306.11565}, year = {2023} }
Acknowledgments
The HomeRobot OVMM would not have been possible without the infrastructure and support of Hello Robot 2 and EvalAI 3 team.
References
- 1.
- ^ a b Habitat: A Platform for Embodied AI Research. Manolis Savva*, Abhishek Kadian*, Oleksandr Maksymets*, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, Dhruv Batra. ICCV, 2019.
- 2.
- ^ a b c The Design of Stretch: A compact, lightweight mobile manipulator for indoor human environments. Charles C. Kemp, Aaron Edsinger, Henry M. Clever, and Blaine Matulevich. ICRA, 2022.
- 3.
- ^ a b Eval AI: Towards Better Evaluation Systems for AI Agents. Deshraj Yadav, Rishabh Jain, Harsh Agrawal, Prithvijit Chattopadhyay, Taranjeet Singh, Akash Jain, Shiv Baran Singh, Stefan Lee, Dhruv Batra. SOSP, 2019.
- 4.
- ^ Benchmarking in Manipulation Research: The YCB Object and Model Set and Benchmarking Protocols. Berk Calli, Aaron Walsman, Arjun Singh, Siddhartha Srinivasa, Pieter Abbeel, Aaron M. Dollar. Robotics and Automation Magazine (RAM), 2015.
- *.
- ^ Subject to international laws governing commerce and shipping restrictions.
Organizer and Sponsor

|

|

|