Habitat Challenge 2022
Overview
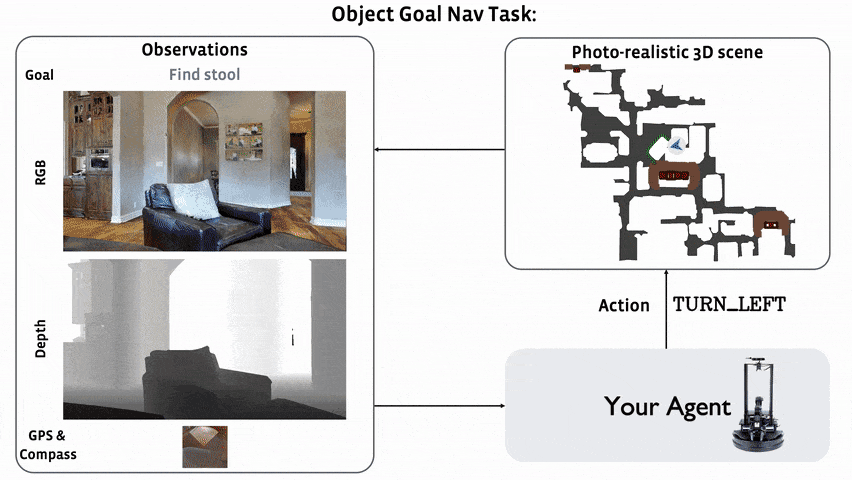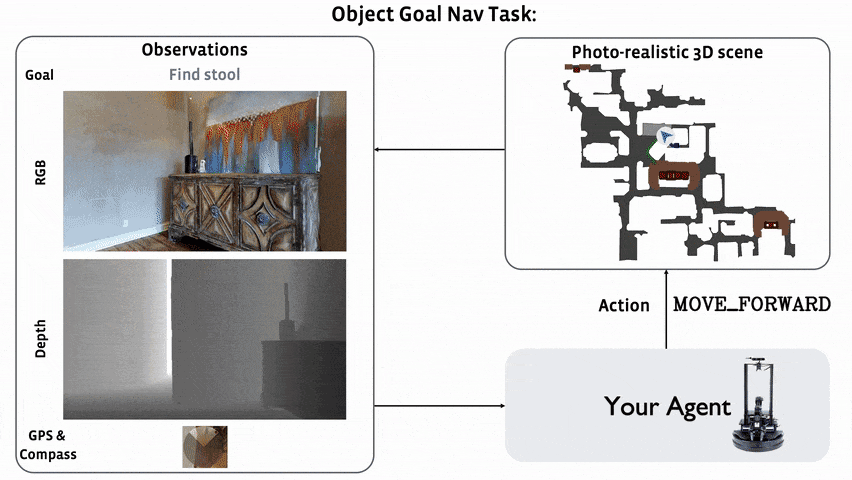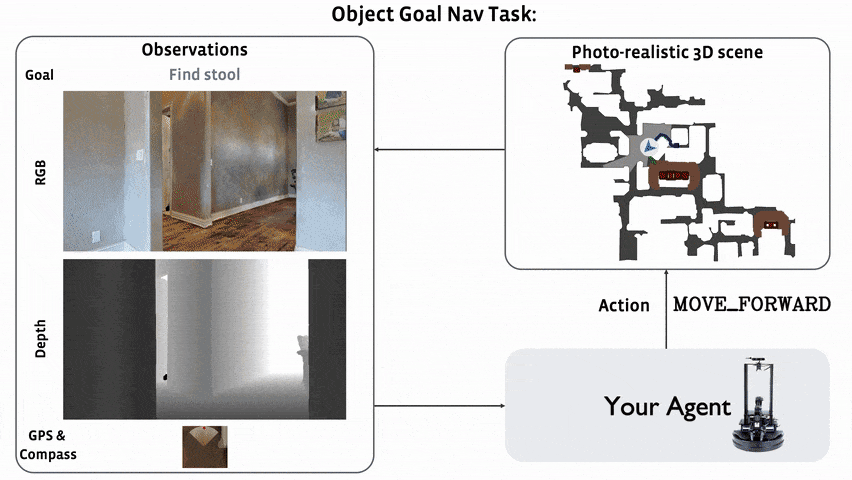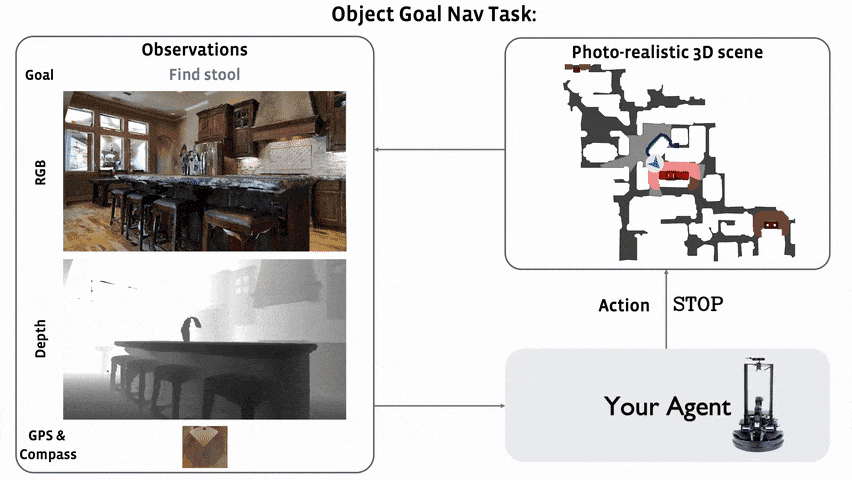
In 2022, we are hosting the ObjectNav challenge in the Habitat simulator 1. ObjectNav focuses on egocentric object/scene recognition and a commonsense understanding of object semantics (where is a bed typically located in a house?).
For details on how to participate, submit and train agents refer to github.com/habitat-challenge repository.
New in 2022
- We are instantiating ObjectNav on a new dataset called HM3D-Semantics v0.1.
- We are retiring the PointNav challenge, although the evaluation servers will continue to be open and researchers are welcome to submit to them.
Task: ObjectNav
In ObjectNav, an agent is initialized at a random starting position and orientation in an unseen environment and asked to find an instance of an object category (‘find a chair’) by navigating to it. A map of the environment is not provided and the agent must only use its sensory input to navigate.
The agent is equipped with an RGB-D camera and a (noiseless) GPS+Compass sensor. GPS+Compass sensor provides the agent’s current location and orientation information relative to the start of the episode. We attempt to match the camera specification (field of view, resolution) in simulation to the Azure Kinect camera, but this task does not involve any injected sensing noise.
Dataset
The 2022 ObjectNav challenge uses 120 scenes from the Habitat-Matterport3D (HM3D) Semantics v0.1 2 dataset with train/val/test splits on 80/20/20. Following Chaplot et al. 3, we use 6 object goal categories: chair, couch, potted plant, bed, toilet and tv.
Evaluation
Similar to 2021 Habitat Challenge, we measure performance along the same two axes as specified by Anderson et al. 4:
- Success: Did the agent navigate to an instance of the goal object? (Notice: any instance, regardless of distance from starting location.)
Concretely, an episode is deemed successful if on calling the STOP action, the agent is within 1.0m Euclidean distance from any instance of the target object category AND the object can be viewed by an oracle from that stopping position by turning the agent or looking up/down. Notice: we do NOT require the agent to be actually viewing the object at the stopping location, simply that the such oracle-visibility is possible without moving. Why? Because we want participants to focus on navigation not object framing. In Embodied AI’s larger goal, the agent is navigating to an object instance to interact with it (say point at or manipulate an object). Oracle-visibility is our proxy for ‘the agent is close enough to interact with the object’.
- SPL: How efficient was the agent’s path compared to an optimal path? (Notice: optimal path = shortest path from the agent’s starting position to the closest instance of the target object category.)
After calling the STOP action, the agent is evaluated using the ‘Success weighted by Path Length’ (SPL) metric4.
ObjectNav-SPL is defined analogous to PointNav-SPL. The only key difference is that the shortest path is computed to the object instance closest to the agent start location. Thus, if an agent spawns very close to ‘chair1’ but stops at a distant ‘chair2’, it will be achieve 100% success (because it found a ‘chair’) but a fairly low SPL (because the agent path is much longer compared to the oracle path).
We reserve the right to use additional metrics to choose winners in case of statistically insignificant SPL differences.
Participation Guidelines
Participate in the contest by registering on the EvalAI challenge page and creating a team. Participants will upload docker containers with their agents that evaluated on a AWS GPU-enabled instance. Before pushing the submissions for remote evaluation, participants should test the submission docker locally to make sure it is working. Instructions for training, local evaluation, and online submission are provided below.
Valid challenge phases are habitat-objectnav-{minival, test-standard, test-challenge}-2022-1615.
The challenge consists of the following phases:
- Minival phase: This split is same as the one used in
./test_locally_objectnav_rgbd.sh. The purpose of this phase is sanity checking — to confirm that our remote evaluation reports the same result as the one you’re seeing locally. Each team is allowed maximum of 100 submissions per day for this phase, but please use them judiciously. We will block and disqualify teams that spam our servers. - Test Standard phase: The purpose of this phase/split is to serve as the public leaderboard establishing the state of the art; this is what should be used to report results in papers. Each team is allowed maximum of 10 submissions per day for this phase, but again, please use them judiciously. Don’t overfit to the test set.
- Test Challenge phase: This split will be used to decide challenge winners. Each team is allowed total of 5 submissions until the end of challenge submission phase. The highest performing of these 5 will be automatically chosen. Results on this split will not be made public until the announcement of final results at the Embodied AI workshop at CVPR.
Note: Your agent will be evaluated on 1000 episodes and will have a total available time of 48 hours to finish. Your submissions will be evaluated on AWS EC2 p2.xlarge instance which has a Tesla K80 GPU (12 GB Memory), 4 CPU cores, and 61 GB RAM. If you need more time/resources for evaluation of your submission please get in touch.
Results
Habitat Challenge 2022 Workshop talk:
Habitat Challenge 2022 Workshop talk slides: download.
Citing Habitat Challenge 2022
@misc{habitatchallenge2022, title = Habitat Challenge 2022, author = {Karmesh Yadav and Santhosh Kumar Ramakrishnan and John Turner and Aaron Gokaslan and Oleksandr Maksymets and Rishabh Jain and Ram Ramrakhya and Angel X Chang and Alexander Clegg and Manolis Savva and Eric Undersander and Devendra Singh Chaplot and Dhruv Batra}, howpublished = {\url{https://aihabitat.org/challenge/2022/}}, year = {2022} }
Acknowledgments
The Habitat challenge would not have been possible without the infrastructure and support of EvalAI team.
References
- 1.
- ^ Habitat: A Platform for Embodied AI Research. Manolis Savva*, Abhishek Kadian*, Oleksandr Maksymets*, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, Dhruv Batra. ICCV, 2019.
- 2.
- ^ Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI. Santhosh K. Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X. Chang, Manolis Savva, Yili Zhao, Dhruv Batra. arXiv:2109.08238, 2021.
- 3.
- ^ Object Goal Navigation using Goal-Oriented Semantic Exploration. Devendra Singh Chaplot, Dhiraj Gandhi, Abhinav Gupta, Ruslan Salakhutdinov. NeurIPS, 2020.
- 4.
- ^ a b On evaluation of embodied navigation agents. Peter Anderson, Angel Chang, Devendra Singh Chaplot, Alexey Dosovitskiy, Saurabh Gupta, Vladlen Koltun, Jana Kosecka, Jitendra Malik, Roozbeh Mottaghi, Manolis Savva, Amir R. Zamir. arXiv:1807.06757, 2018.
Dates
| Challenge starts | February 14, 2022 |
| Leaderboard opens | March 1, 2022 |
| Challenge submission deadline | August 31, 2022 |
Organizer
Participation
For details on how to participate, submit , and train agents, refer to github.com/habitat-challenge repository.